Redshift vs. BigQuery: Comparing the Best Data Warehouses
Amazon’s Redshift vs. Google’s BigQuery Detailed Comparison. Best data warehouse. Data warehouses are compared on pricing, usability, and performance.

All organisations spread across multiple domains have one point of management in common: data. Be it an e-commerce industry that needs to keep track of umpteen customers and their buying preferences, or the healthcare industry that needs to store information about the maximum amount of medicines and its consumers, Physically storing huge volumes of data is a thing of the past, and all the companies are now pacing towards cloud-based technologies to take care of data storage, analysis, and overall management. We need a data warehouse to accomplish the same.
A data warehouse is a centralised data storage system that collects data from various sources and supports analytics and other business intelligence activities. The data stored in the warehouse comes from a variety of heterogeneous resources, ranging from log files and events to relational databases. In a data warehouse, data is not real-time; hence, the focus is on analytical queries and the strategic use of data for business decisions. Fast-paced and growth-oriented businesses rely on this data for reports, analysis, and dashboards to extract insights and monitor their performance.
The two major providers of cloud-based data warehouses in current times are Redshift and BigQuery. Redshift belongs to Amazon, whereas BigQuery is owned by Google. Let us do a deep dive into comparing these two and learning more about each of them, and then we will cover an in-depth analysis of Amazon RedShift vs. Google BigQuery so that you can draw a constructive conclusion.
Redshift
Redshift is an impressive, fully managed data warehousing solution by Amazon that can store data ranging from a few gigabytes to a petabyte or more, depending on the business requirements. The key highlights of Redshift include parallel processing and data compression, which allow it to process as many as a billion rows simultaneously. Not just that, it also takes care of the security and other aspects of the data at no additional cost. Data is stored in a set of computed resources called nodes. These form groups of clusters in Redshift, which can be further divided into slices to help attain deeper insights into the data.
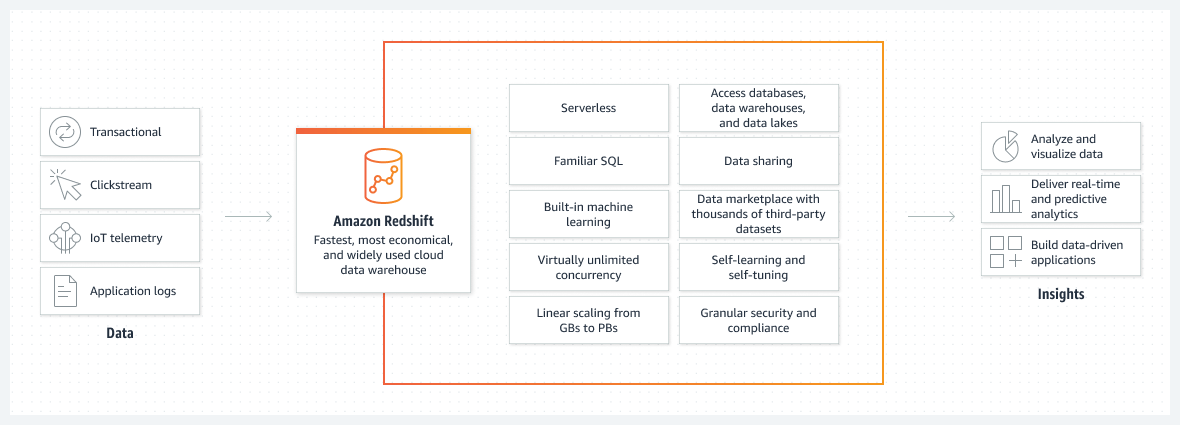
Key features of Redshift
- Something for everyone
No matter what your business requirements are, they are most likely to be met by Redshift. Amazon Redshift Serverless can be used to run and scale analytics within a short period of time, whereas Query Editor v2 brings the ease of SQL into the world of data engineers and data analysts. Though you can visualize query results through the query editor and create tables and ad data visually, Moreover, the Redshift Data API makes accessing and updating data as easy as hitting an API and supports major programming languages such as Python, Go, Java, Node.js, PHP, Ruby, and C++.
- Data Analysis made simple
Redshift makes it easy to query as well as export data to and from your data warehouse. Using ANSI SQL, open file formats like JSON and CSV can be queried directly in S3. Exporting the data can be done through the UNLOAD command in Redshift by specifying the format of the output file. Apart from that, Redshift provides AWS service integration and data sharing among different AWS accounts across different regions. It also supports advanced analytical processing.
- Scalability without compromising performance
Using technologies like Advanced Query Accelerator and RA3 instances, Redshift optimizes its query speed to a great extent. Queries in Redshift also make use of machine learning and result caching to deliver faster results.
- Top-notch security
Amazon uses end-to-end encryption and network isolation to offer the best security to its consumers. Not only that, it integrates with AWS CloudTrail, through which an organization can audit all Redshift API calls.
Google BigQuery
Another great enterprise data warehouse alternative is Google BigQuery. This data warehousing solution is fully managed as well, along with being scalable and serverless, which means you do not have to set up or manage any infrastructure. The range of features offered by BigQuery at a cost-effective model is super impressive and attracts many consumers. Let us dive deep into the salient features of BigQuery.

Features of BigQuery
- Multi-cloud Functionality
Without charging an extravagant amount of money, BigQuery allows us to analyze data present in more than one cloud. It achieves this by decoupling its storage and compute components.
- ML Integration
Google BigQuery has built-in ML integration, which can be used to create and execute machine learning models with the help of simple SQL queries. This eliminates the need to build ML solutions and provides the ability to programme and execute ML models using spreadsheets and existing BI tools.
- Speed and simplicity
BigQuery uses a BI engine that ensures high concurrency and quick response times. It can easily process up to billions of rows in a very short time.
- Automated Data Transfer
Data transfer into BigQuery is a simple and automated process that does not involve coding. Retry mechanisms can also be introduced in cases of issues or any possible server errors. You can also load data from other data warehouses, like Redshift and TeraData, into Google BigQuery.
Comparison
Both of the data warehouses by Amazon and Google are efficient and robust and are backed by a lot of great consumers, but is one of these better than the other? Which one of the two ultimately wins the battle of Amazon RedShift vs. Google BigQuery? Well, it depends entirely on your business requirements. Let us do a detailed BigQuery vs. RedShift comparison for you to take a call on which warehouse suits your needs better.
RedShift vs. BigQuery in Performance
In terms of performance, BigQuery vs. RedShift is a close call. BigQuery’s pricing is based on the volume of data that you process, whereas RedShift is limited by the node you're running on, which is what you should consider when looking for performance. Since both of these are backed by tech giants, there is no considerable difference in performance that can be highlighted. Depending on the kind of queries that will be run, you can try both out. Redshift and BigQuery both offer free trial periods where customers can evaluate performance, but there is a limit on available resources during those periods.
RedShift vs. BigQuery in Scalability
Scalability is limited by three factors: continuous ingestion, tightly coupled storage and compute resources, and a lack of dedicated resources. Scaling in BigQuery is structured and well-planned, as it automatically assigns resources when required. With the on-demand pricing model of BigQuery, it has complete control over the assignment of resources that it provides, whereas in a reserved-slots pricing model, control over resources is more limited, which aids in scalability.
Even with RA3, Redshift cannot distribute the workload across clusters. To support query concurrency, it can scale up to 10 clusters, but Redshift can only bear a maximum of 50 queued queries across all clusters by default.
RedShift vs. BigQuery in Manageability
Even though both of the warehouses are serverless, Redshift needs you to have a basic understanding of nodes and clusters, both creating and allocating them if required. Moreover, Redshift also requires periodic management activities, like cleaning up or vacuuming tables to delete entries.
For BigQuery, we need no such knowledge. You can simply create a project on GCP, enable BigQuery on it, and run a query. As specified above, Google automatically scales in the background to meet scalability needs.
RedShift vs. BigQuery in Usability
If we consider usability, BigQuery is a clear winner, as BigQuery's SQL-like user interface helps engineers and analysts get their tasks done without requiring any additional skills. It abstracts the details of the hardware, database, and other configurations. Redshift, on the other hand, requires a basic knowledge of warehousing concepts, nodes, clusters, and their management, which could take up to a few weeks to get a hang of.
RedShift vs. BigQuery in Security
In terms of security, both companies have a robust system. Amazon RedShift uses Amazon IAM for identity, whereas Google BigQuery uses Google Cloud IAM. Both warehouses support encryption and include VPC and SSL connections.
A point worth mentioning here is that Google has impressive B2B identity management with OAuth, which means that an organization can give identity controls to third-party systems to allow them to perform specific operations without exposing their entire ecosystem to them. In the same manner, an organization can grant a specific set of permissions to a user for a specific cluster in Redshift.
RedShift vs. BigQuery in Pricing
On a macroscopic level, both services have two types of pricing: pay-per-use or on-demand pricing and reserve or flat-rate pricing.
Google BigQuery charges for storage, inserts, and queries individually, whereas in RedShift, you are charged for each node in clusters. For BigQuery, storage costs around $20 per TB per month, and the queries cost around $5 per month. In the case of RedShift, the cheapest node available is around $0.25 per hour. Note that for RedShift, the price covers both storage and processing.
If you are looking to perform everyday data warehouse operations, RedShift will be the ideal choice for you, but in cases of extremely variable workloads and data mining operations, BigQuery would be a better choice.
Both BigQuery and RedShift are excellent choices for businesses to assist them in their analytics and growth. Google BigQuery vs. Redshift is a tight call, but the above factors should help you make an informed decision. Whichever of the two data warehouses you choose, Draxlr has support for that, which can solve the rest of your worries.
After registering on Draxlr here, https://app.draxlr.com/, you can choose the manual setup option, and you will land on the add database page.

Redshift with Draxlr
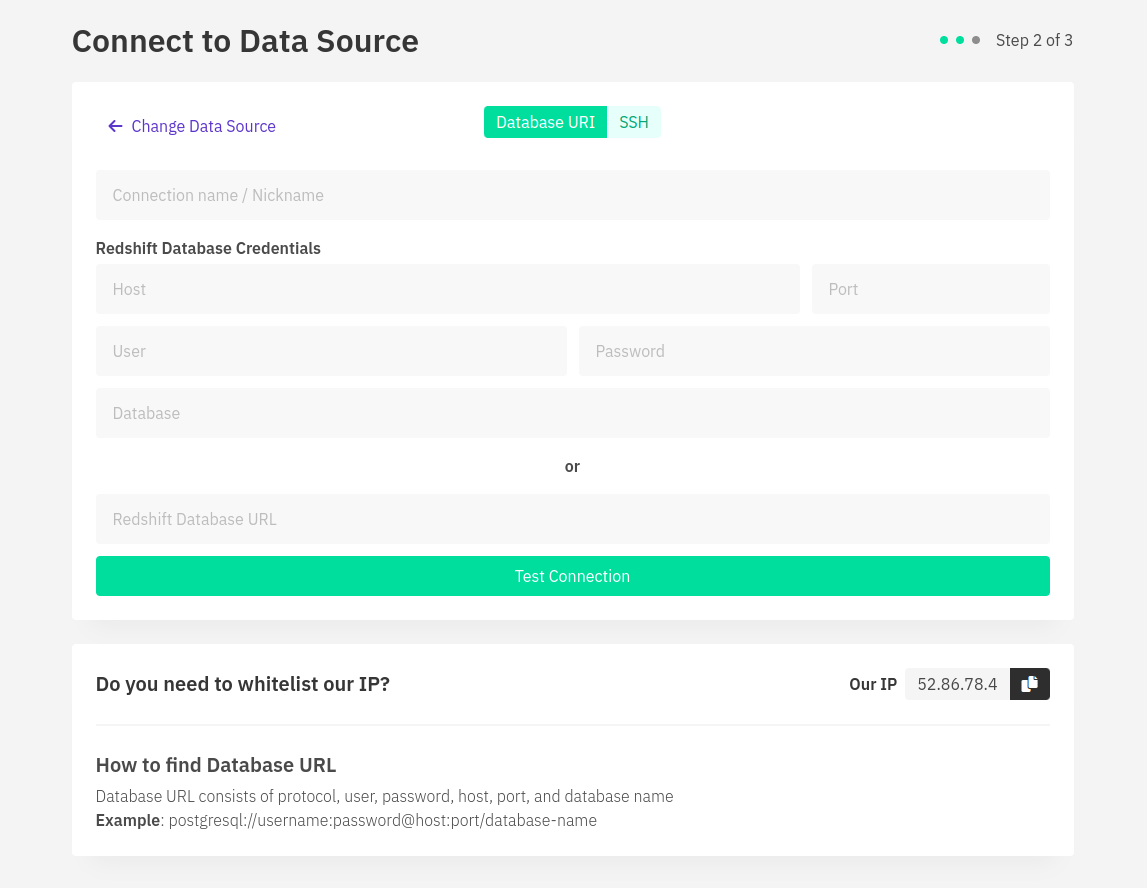
On the database page, you can choose Redshift and then provide the connection details like your host, port, user, password, and database name. Alternatively, you can also provide the RedShift Database URL. After the connection is successful, you can access all your data through Draxlr.
BigQuery with Draxlr
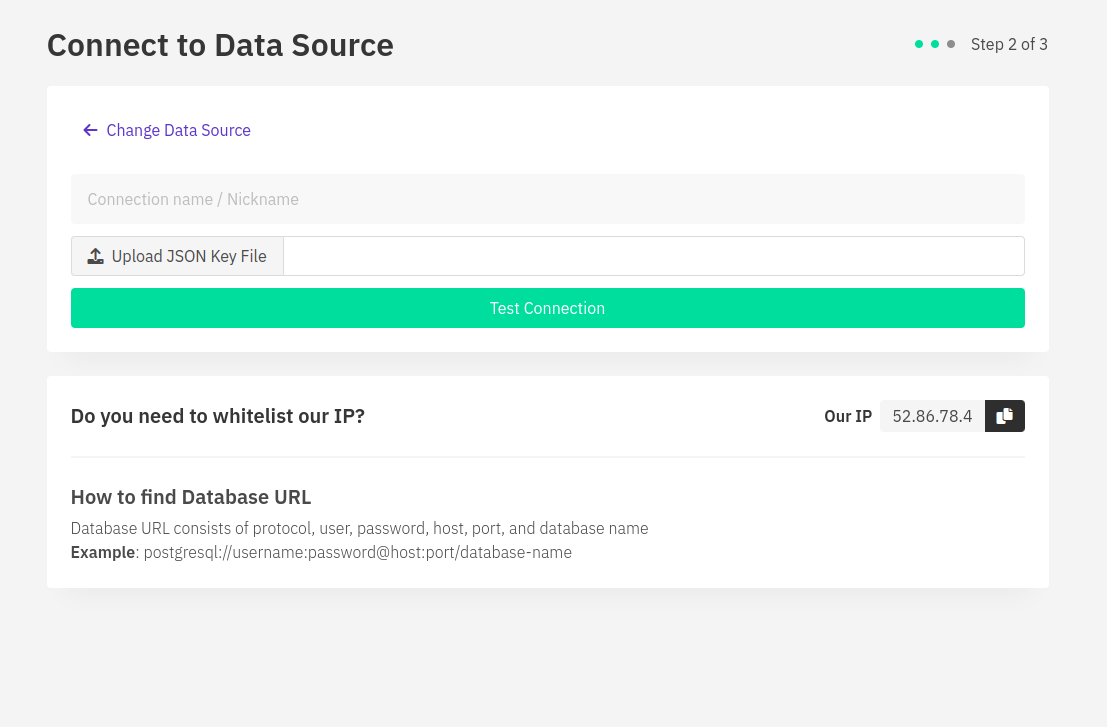
If you want to move ahead with BigQuery, you can select BigQuery and then provide the JSON key file and your connection name. After the connection is successful, you can access all your data through Draxlr.
Choosing the right data warehouse, especially if it is backed by major tech giants like Amazon Redshift and Google BigQuery, is one of the most crucial steps in building an organization. It needs a lot of research and insights, as the growth and analytics of the company depend on the warehouse. The above points were an attempt to take you a step closer to your decision, and remember that no matter which of the two you choose, Draxlr is right here to back you up! We support both of these data resources, along with a lot of other categories of databases, which you can check out here. I hope you make the right decision!

