YugabyteDB or CockroachDB: which is better distributed SQL database?
CockroachDB versus YugabyteDB comparison in scalability, security, and ACID properties What is distributed SQL? CockroachDB features vs. YugabyteDB features in distributed SQL database choices

For any business to flourish, its database management system has to be durable, reliable, and consistent. From storing customer, order, and other details in an e-commerce business to storing investment and transaction details in a fintech company, data is the most vital point for any organization. With database management done correctly, the other crucial aspects of the business, like data analytics, sales, marketing, and ad campaigns, all of which heavily rely on data, simplify by a large amount, which directly impacts the growth and revenue of the company.
NoSQL and SQL databases are the two major categories of databases to choose from, and they have their own pros and cons. Choosing the right kind of database, which is currently a tradeoff between scalability and consistency, is important. In a relational SQL database, scaling to keep up with large volumes of data is a weak point, while in a NoSQL database, data integrity and consistency are compromised. This is where a need arises for a third alternative that is scalable as well as consistent, and distributed SQL fits into this role quite well. A distributed SQL is a relational database that is deployed on a cluster of network servers, which are also referred to as nodes. Multiple instances of a database come together in distributed SQL, where each instance is solely responsible for the storage and maintenance of a particular dataset.
The two most popular choices of database in the cloud-native distributed domain are CockroachDB and YugabyteDB. For new businesses, CockroachDB vs. YugabyteDB can be an overwhelming choice, and hence, here is a brief introduction of both along with their salient features.
YugabyteDB

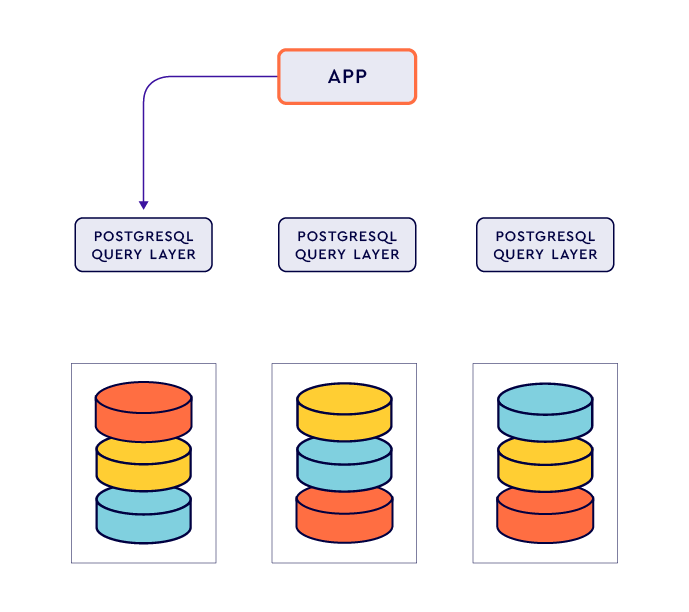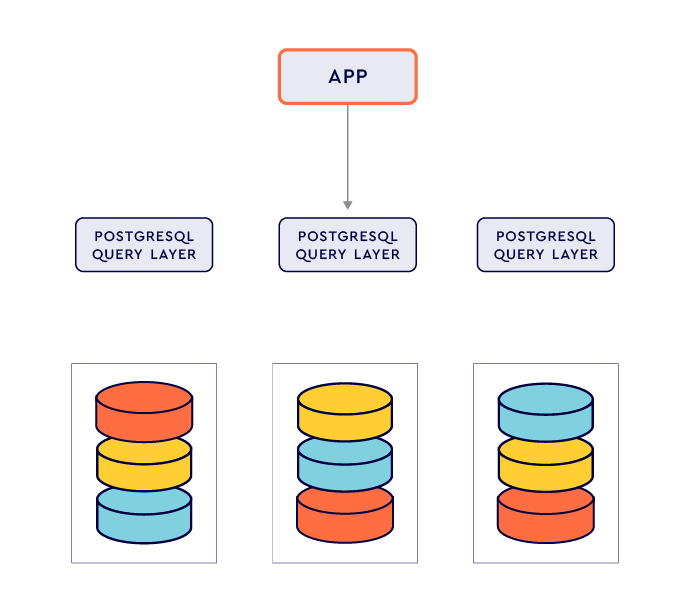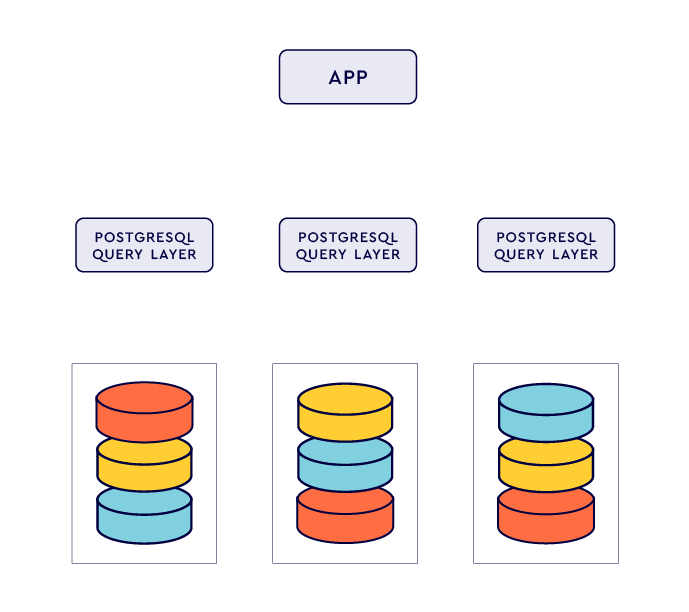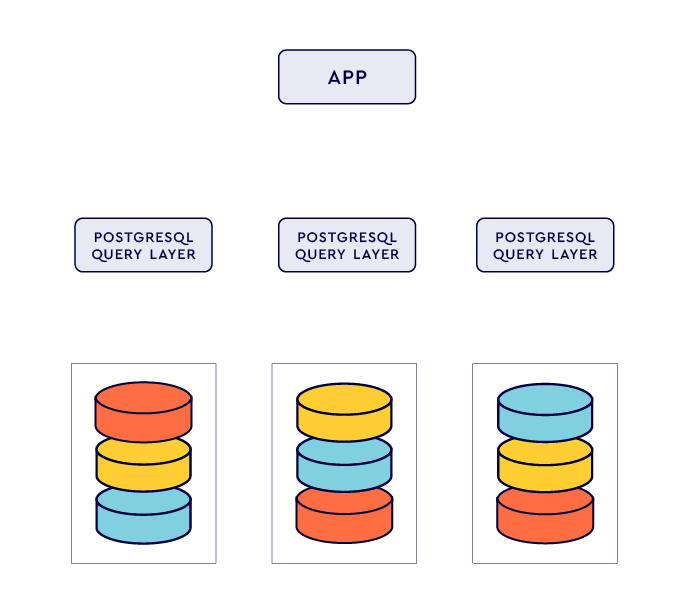
Designed around the CAP theorem, this open-source cloud-native distributed SQL is compatible with PostgreSQL, which is currently one of the most popular database choices for relational databases. It also implies that any application that has PostgreSQL integration can be easily migrated to YugabyteDB. YugabyteDB brings a lot to the table, namely high availability, scalability, and consistency. For high availability, YugabyteDB makes use of replicas, whereas to achieve scalability, it uses partitions, which are also called tablets. Two layers primarily constitute the building blocks of YugabyteDB: DocDB, which is the storage engine and is abstracted from users, and the Query Layer, which is responsible for query execution and optimisation.
Features of YugabyteDB
- Easy Compatibility with Postgres
The first decision that any business wanting to migrate to YugabyteDB has to face is whether the transition will be smooth, and YugabyteDB’s ability to reuse any application’s PostgreSQL query layer is one of its strongest points. PostgreSQL is a popular choice of database in relational database systems, and hence YugabyteDB’s support of PostgreSQL makes it stand out.
- High Scalability
Unlike SQL databases, YugabyteDB claims to scale up to 300,000 database transactions per second, which means that the database has the capability to scale up and down according to the requirements of the application. The performance of the database can be increased by adding nodes. It can also store a maximum of 100 TB of data and facilitate concurrent connections, all of which make it a popular choice for distributed SQL databases.
- High Availability
Common issues faced with databases are failed backups and unexpected downtime. YugabyteDB is continuously available, which is possible through distributed backups and occasional data synchronisation activities across the nodes. The maintenance operations are also run without downtime, which is also a remarkable feature. Multi-region deployments and replication also ensure availability.
- Hybrid functionality and multi-cloud capabilities
With YugabyteDB, the application can be deployed anywhere, i.e., in private, public, or hybrid cloud environments. Giving the application the freedom to be run anywhere reduces costs and avoids vendor lock-in.
CockroachDB

Founded in 2015, this database gets its name from the resilience of cockroaches, who are impossible to take down, hence the name CockroachDB. Based on a strongly consistent key-value store, this consistently distributed database also follows the ACID properties (Atomicity, Consistency, Isolation, and Durability). It provides a SQL API for querying and performing other operations on data.
Features of CockroachDB
- Geographic Zone Configurations
In setting up CockroachDB nodes, the control of where the data is stored is with the database administrator or the developer. The nodes or cluster of network servers in CockroachDB are tagged with attributes and hierarchical localities, which makes them easy to identify. It also ensures zero downtime for data migrations.
- Follower Reads (limited to the Enterprise version)
In this feature, any replica of a range can attend to a read request, which should, however, have been sufficient in the past. This is achieved by using the AS OF SYSTEM TIME clause in the CockroachDB. Through follower reads, the latency of the read operations goes down by a huge margin, which also promotes increased throughput. Here, the replica, which is geographically situated closest to the gateway, is allowed to serve the read request, considering it contains slightly historical data—at least 48 seconds in the past.
- Ability to use semi-structured data
The latest version of CockroachDB (>2.0) supports JSON and JSONB, which are semi-structured data types, which is one of the benefits provided by NoSQL databases. Many applications require the functionality of databases that can intuitively map to OOP languages without having to model the data in a completely normalised way. Moreover, by adding general inverted indexes to the JSON columns, the query operations become much faster, making the application run smoother and quicker.
- Better backup and restoration facilities
As the name itself suggests, CockroachDB is built for resilience, but that does not mean that the backups and restore facilities can be strung by a loose thread. Low-level node failures are not to be worried about, and the backup mechanism is built for situations wherein a cluster loses most of its nodes or other such situations. A full or incremental backup of an application’s database can be created through CockroachDB’s Backup statement. The restore statement restores the cluster schemas from any cloud-based or local storage.
The above-listed properties of CockroachDB and YugabyteDB can be present in both database choices and are not limited to any one database. Detailed comparisons of the performance of each database, along with comparing them alongside each other, i.e., CockroachDB vs. YugabyteDB, have been released by both companies. Here are YugabyteDB’s two cents on the CockroachDB vs. YugabyteDB battle, whereas here can see CockroachDB’s take on it. The database you choose for your application can be either of the two, depending on many factors, primarily budget, business, scale, and security requirements.
Setting up on Draxlr
CockroachDB vs. YugabyteDB is a decision you would have to make, but Draxlr is here to make the next steps easy for you. No matter which of the two you choose, Draxlr supports both distributed database systems, which will ease your data analytics side of the business by making complex dashboards and setting up alerts on the data in no time.
To begin with, you will need to register on Draxlr here: https://app.draxlr.com/, after which you can select the manual setup option. This will then navigate you to the “Add database” page, where you can select either CockroachDB or YugabyteDB. Before moving forward, please note that your database should be allowed to accept connections from Draxlr’s IP listed on the connections page.
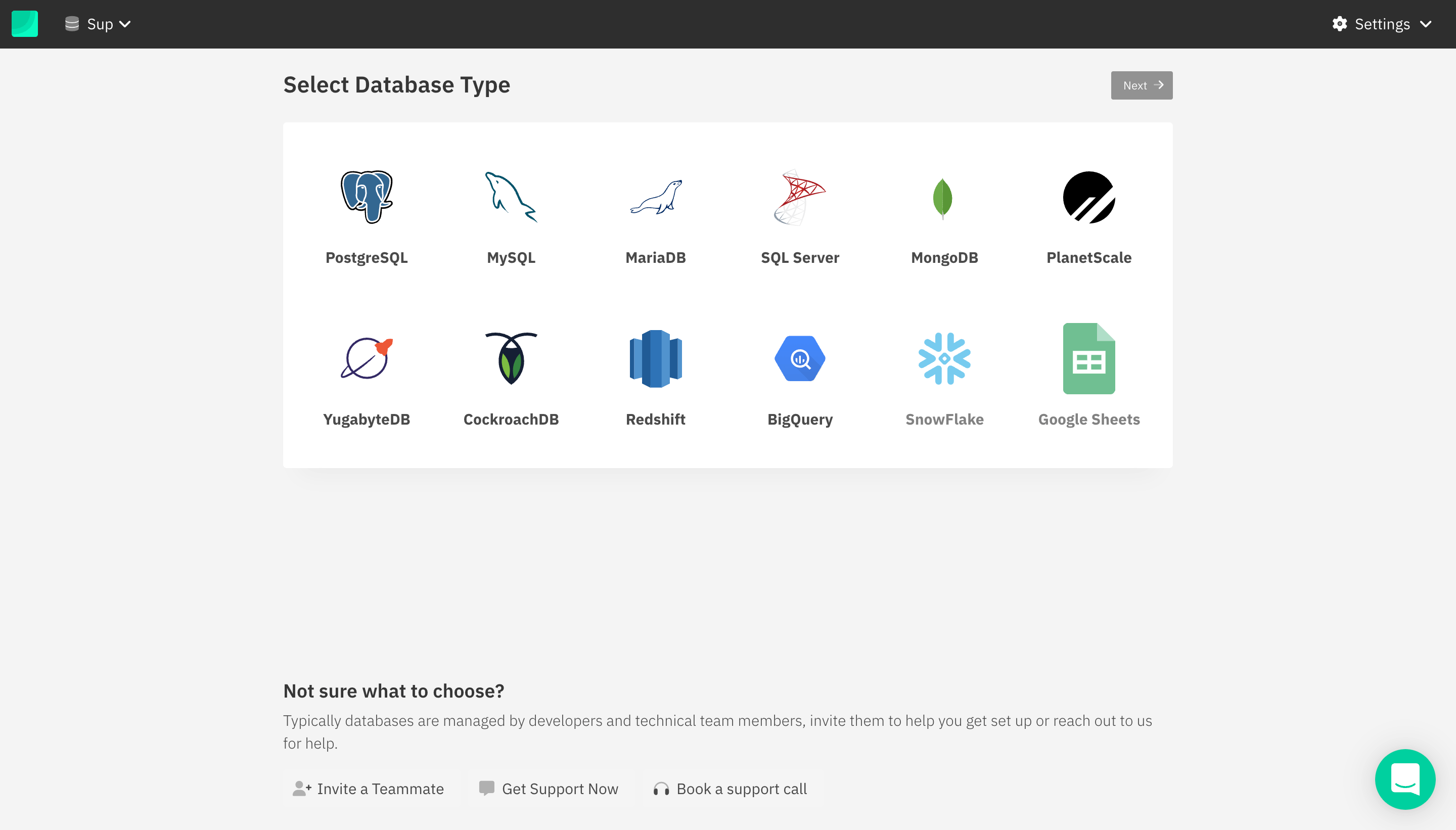
Setting up CockroachDB with Draxlr
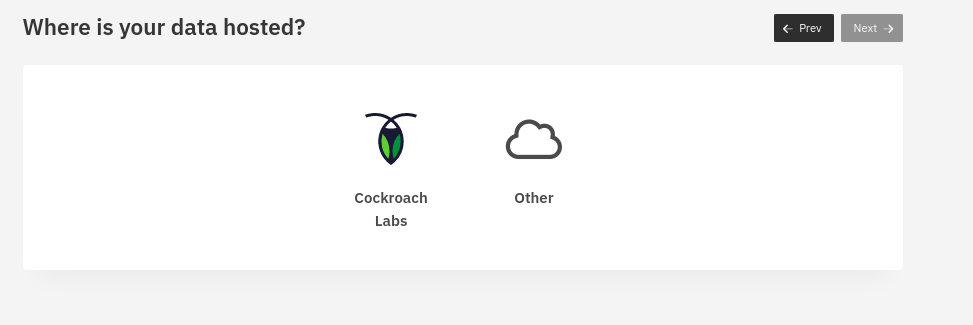
On the add database page, select CockroachDB, and then click on the Next button on the top right of the section. It will then ask you where your data is hosted, depending on whether you select Cockroach Labs or Other. You can provide connection details like your host, port, user, password, and database name.
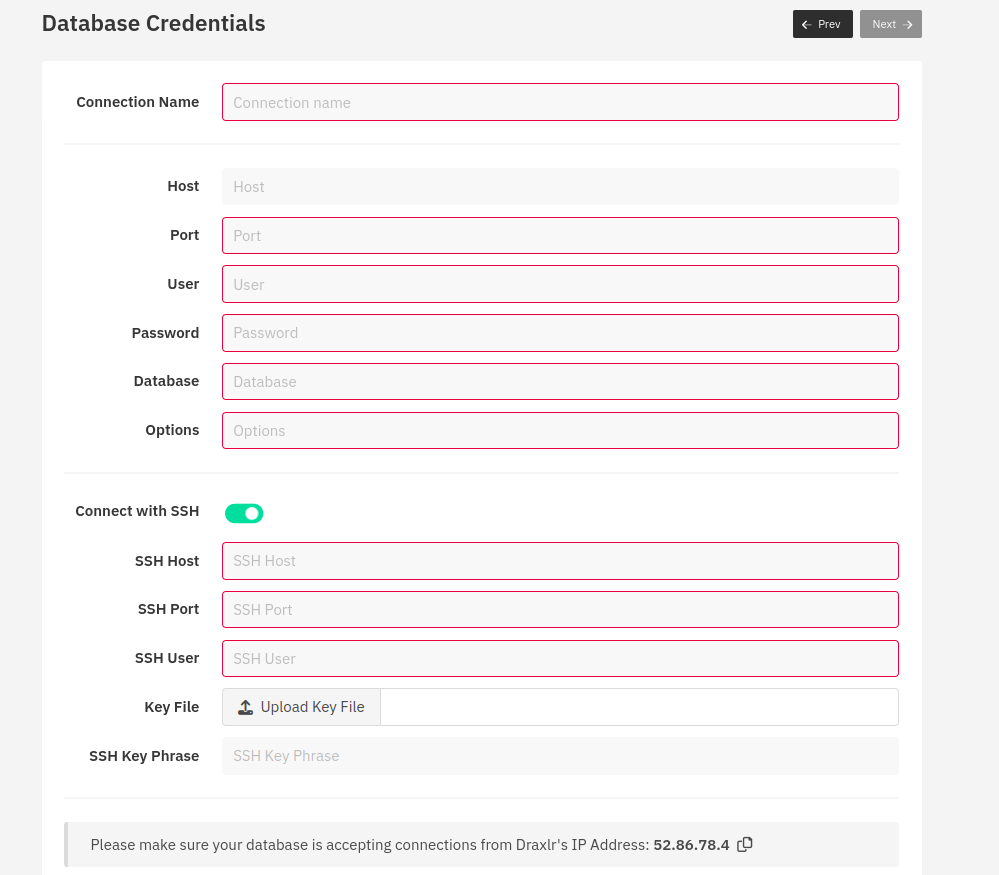
You can also provide an SSH host, port, user, and key file to be able to connect to the database via SSH. Once done, you can access your data via Draxlr.
For more details on how to build dashboards from Cockroach DB data, you can check out this article.
Setting up YugabyteDB with Draxlr
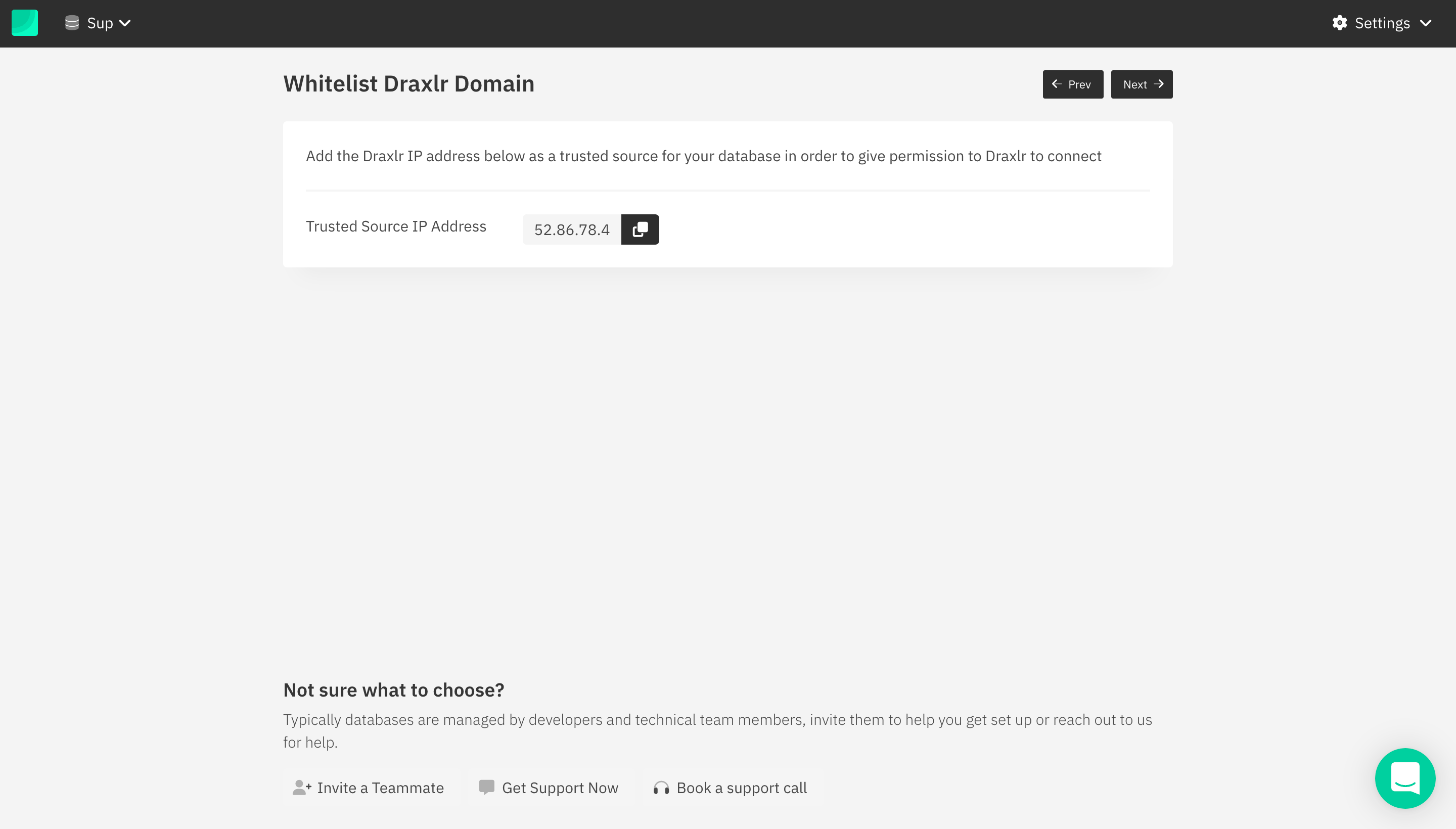
If you want to move forward with YugabyteDB, click on the YugabyteDB icon, and then click on the Next button on the top right of the section. You will see a public IP address belonging to Draxlr, which should be added as a trusted source for your database.
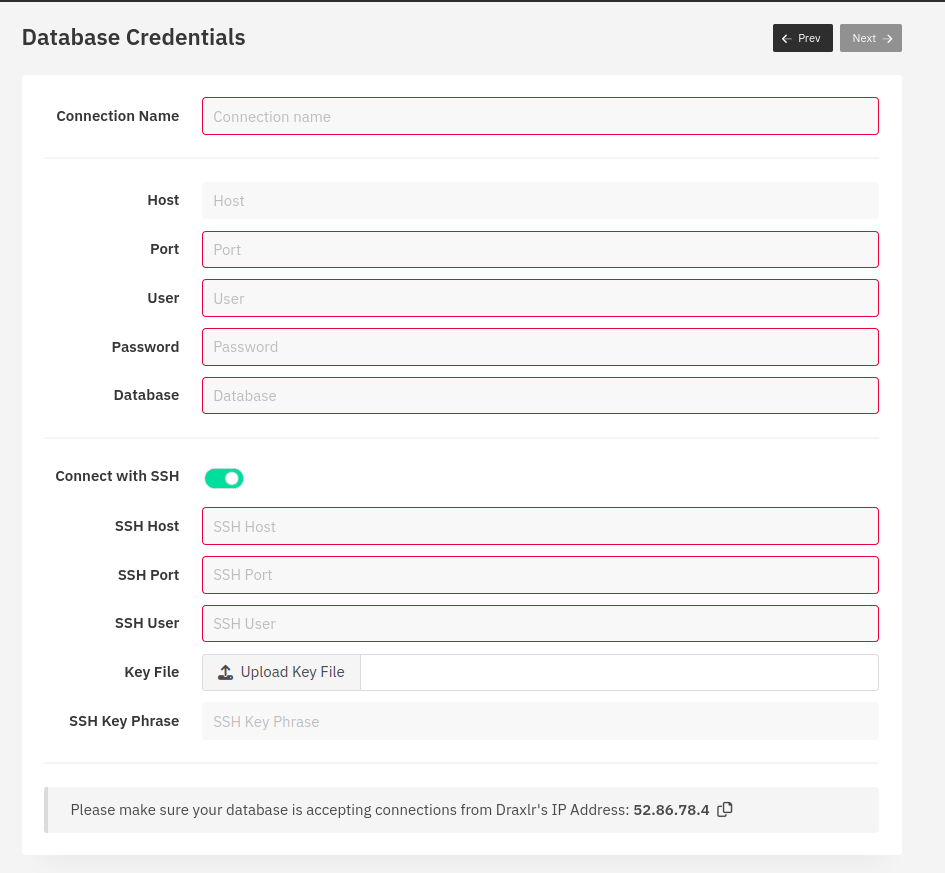
Once that is done, you can fill in the connection details like database host, port, user, password, and database name. You can also provide an SSH host, port, user, and key file to be able to connect to the database via SSH. That’s it!
Choosing the correct database for your application can be an overwhelming decision, and hence, you should take your time and go through all the available options with the utmost attention. CockroachDB vs. YugabyteDB is a choice that only you can make for your application, but Draxlr is right here to take care of the next steps. From dashboard creation to slack and email alerting to supporting many database choices, Draxlr has got you covered! Happy indexing and transacting! (After choosing the correct database, of course.)

